
Comment produire automatiquement des titres de qualité et des méta descriptions
En ces temps difficiles, il est plus important que jamais d’obtenir un travail plus efficace en moins de temps et avec moins de ressources.
Une tâche de référencement ennuyeuse et chronophage qui est souvent négligée consiste à rédiger des titres convaincants et des méta descriptions à grande échelle.
En particulier, lorsque le site comporte des milliers ou des millions de pages.
Il est difficile de faire l’effort lorsque vous ne savez pas si la récompense en vaudra la peine.
Dans cette colonne, vous apprendrez à utiliser les dernières avancées en matière de compréhension et de génération du langage naturel pour produire automatiquement des titres et des méta descriptions de qualité.
Nous accéderons facilement à cette fonctionnalité de génération passionnante à partir de Google Sheets. Nous apprendrons à implémenter la fonctionnalité avec un minimum de code Python et JavaScript.
Voici notre plan technique:
- Nous mettrons en œuvre et évaluerons quelques modèles récents de synthèse de texte Google Colab
- Nous servirons l’un des modèles d’une fonction Google Cloud que nous pouvons facilement appeler à partir d’Apps Script et de Google Sheets
- Nous allons gratter le contenu de la page directement à partir de Google Sheets et le résumer avec notre fonction personnalisée
- Nous déploierons nos titres et méta descriptions générés comme des expériences dans Cloudflare en utilisant RankSense
- Nous allons créer une autre fonction Google Cloud pour déclencher l’indexation automatisée dans Bing
Présentation des transformateurs de visage étreignant
Étreindre les transformateurs de visage est une bibliothèque populaire parmi les chercheurs et praticiens de l’IA.
Il fournit une interface unifiée et simple à utiliser pour les dernières recherches en langage naturel.
Peu importe si la recherche a été codée en utilisant Tensorflow (Framework Deep Learning de Google) ou Pytorch (Cadre de Facebook). Les deux sont les plus largement adoptés.
Bien que la bibliothèque de transformateurs offre un code plus simple, elle n’est pas aussi simple pour les utilisateurs finaux que Ludwig (J’ai couvert Ludwig dans articles précédents sur l’apprentissage en profondeur).
Cela a changé récemment avec l’introduction du canalisations de transformateurs.
Les pipelines encapsulent de nombreux cas d’utilisation courants du traitement du langage naturel en utilisant un minimum de code.
Ils offrent également une grande flexibilité sur l’utilisation du modèle sous-jacent.
Nous évaluerons plusieurs options de résumé de texte de pointe à l’aide de pipelines de transformateurs.
Nous emprunterons du code à partir des exemples de ce cahier.
Facebook BART
Lors de l’annonce du BART, le chercheur de Facebook Mike Lewis a partagé des résumés abstractifs vraiment impressionnants de leur article.
J’ai trouvé les performances de synthèse étonnamment bonnes – BART semble être capable de combiner des informations provenant d’un document entier avec des connaissances de base pour produire des résumés très abstraits. Quelques exemples typiques ci-dessous: pic.twitter.com/EENDPgTqrl
– Mike Lewis (@ml_perception) 31 octobre 2019
Voyons maintenant à quel point il est facile de reproduire les résultats de leur travail à l’aide d’un pipeline de transformateurs.
Tout d’abord, installons la bibliothèque dans un nouveau bloc-notes Google Colab.
Assurez-vous de sélectionner le runtime GPU.
!pip install transformersEnsuite, ajoutons ceci le code du pipeline.
from transformers import pipeline
# use bart in pytorch
bart_summarizer = pipeline("summarization")Voici l’exemple de texte que nous allons résumer.
TEXT_TO_SUMMARIZE = """
New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
2010 marriage license application, according to court documents.
Prosecutors said the marriages were part of an immigration scam.
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
The case was referred to the Bronx District Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
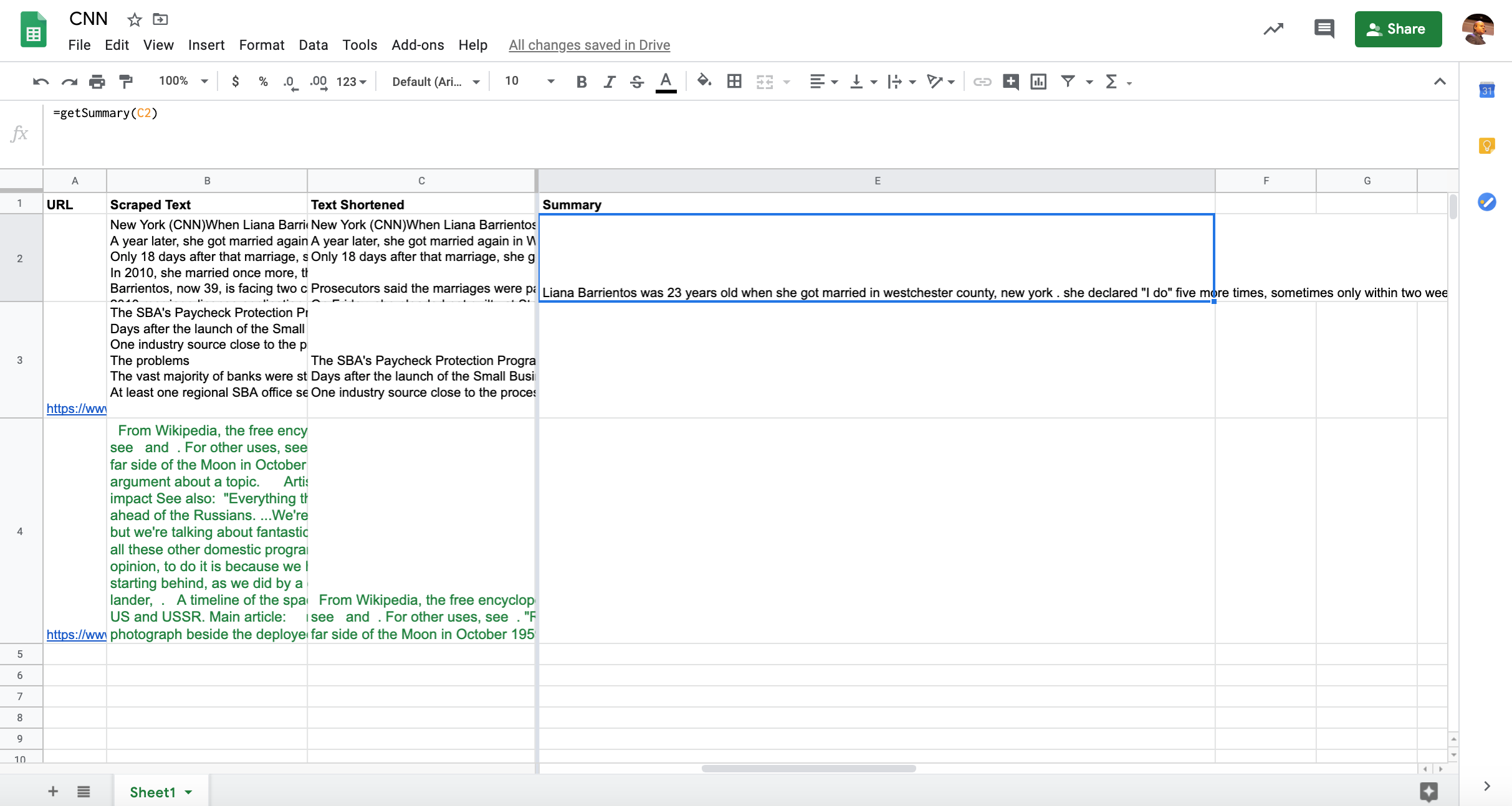
"""Voici le code récapitulatif et le résumé résultant:
summary = bart_summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=250)
print(summary) #Output: [{'summary_text': 'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight at once.'}]J’ai spécifié que le résumé généré ne doit pas contenir moins de 50 caractères et au plus 250.
C’est très utile pour contrôler le type de génération: titres ou méta descriptions.
Maintenant, regardez la qualité du résumé généré et nous n’avons tapé que quelques lignes de code Python.
Super cool!
'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight at once.'
print(len(summary[0]["summary_text"]))
#Output: 249T5 de Google
Un autre modèle de pointe est le Transformateur de transfert de texte à texte, ou T5.
Une réalisation impressionnante du modèle est que ses performances se sont vraiment rapprochées du niveau de référence humain Classement SuperGLUE.
Le modèle de langage T5 (Text-To-Text Transfer Transformer) de Google a établi un nouveau record et se rapproche beaucoup de l’homme sur le benchmark SuperGLUE.https://t.co/kBOqWxFmEK
Papier: https://t.co/mI6BqAgj0e
Code: https://t.co/01qZWrxbqS pic.twitter.com/8SRJmoiaw6– tung (@yoquankara) 25 octobre 2019
Ceci est remarquable car les tâches NLP dans SuperGLUE sont conçues pour être faciles pour les humains mais difficiles pour les machines.
Google a récemment publié un résumé résumé avec tous les détails du modèle pour les personnes moins enclines à en apprendre davantage sur le document de recherche.
Leur idée de base était d’essayer chaque idée populaire de PNL sur un nouvel ensemble de données d’entraînement massif qu’ils appellent C4 (Corpus rampant Colossal Clean).
Je sais, les chercheurs en IA aiment s’amuser à nommer leurs inventions.
Utilisons un autre pipeline de transformateur pour résumer le même texte, mais cette fois en utilisant T5 comme modèle sous-jacent.
t5_summarizer = pipeline("summarization", model="t5-base", tokenizer="t5-base")
summary = t5_summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=250)Voici le texte résumé.
[{'summary_text': 'in total, barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002 . she is believed to still be married to four men, and at one time, she was married to eight men at once .'}]Ce résumé est également de très haute qualité.
Mais j’ai décidé d’essayer le plus grand modèle T5 qui est également disponible en pipeline pour voir si la qualité pourrait s’améliorer.
t5_summarizer_larger = pipeline("summarization", model="t5-large", tokenizer="t5-large")Je n’ai pas été déçu du tout.
Résumé vraiment impressionnant!
[{'summary_text': 'Liana barrientos has been married 10 times . nine of her marriages occurred between 1999 and 2002 . she is believed to still be married to four men, and at one time, she was married to eight men at once .'}]Présentation des fonctions cloud
Maintenant que nous avons du code qui peut résumer efficacement le contenu d’une page, nous avons besoin d’un moyen simple de l’exposer en tant qu’API.
Dans mon article précédent, J’ai utilisé Ludwig sert pour ce faire, mais comme nous n’utilisons pas Ludwig ici, nous allons adopter une approche différente: Fonctions cloud.
Fonctions cloud et équivalent « sans serveur”Les technologies sont sans doute le moyen le plus simple d’obtenir du code côté serveur pour une utilisation en production.
Ils sont sans serveur d’appel car vous n’avez pas besoin de provisionner des serveurs Web ou des machines virtuelles chez les hébergeurs.
Ils simplifient considérablement l’expérience de déploiement comme nous le verrons.
Déployer une fonction cloud Hello World
Nous n’avons pas besoin de quitter Google Colab pour déployer notre premier test de la fonction cloud.
Tout d’abord, connectez-vous à votre compte Google Compute.
!gcloud auth login --no-launch-browserEnsuite, configurez un projet par défaut.
!gcloud config set project project-nameEnsuite, nous allons écrire notre fonction de test dans un fichier nommé main.py
%%writefile main.py
def hello_get(request):
"""HTTP Cloud Function.
Args:
request (flask.Request): The request object.
Returns:
The response text, or any set of values that can be turned into a
Response object using `make_response`
.
"""
return 'Hello World!'Nous pouvons déployer cette fonction à l’aide de cette commande.
!gcloud functions deploy hello_get --runtime python37 --trigger-http --allow-unauthenticatedAprès quelques minutes, nous obtenons les détails de notre nouveau service API.
availableMemoryMb: 256
entryPoint: hello_get
httpsTrigger:
url: https://xxx.cloudfunctions.net/hello_get
ingressSettings: ALLOW_ALL
labels:
deployment-tool: cli-gcloud
name: projects/xxx/locations/us-central1/functions/hello_get
runtime: python37
serviceAccountEmail: xxxx
sourceUploadUrl: xxxx
status: ACTIVE
timeout: 60s
updateTime: '2020-04-06T16:33:03.951Z'
versionId: '8'C’est ça!
Nous n’avions pas besoin de configurer de machines virtuelles, de logiciels de serveur Web, etc.
Nous pouvons le tester en ouvrant l’URL fournie et en obtenant le texte « Hello World! » comme réponse dans le navigateur.
Déployer notre fonction Cloud de synthèse de texte
En théorie, nous devrions pouvoir encapsuler notre pipeline de récapitulation de texte dans une fonction et suivre les mêmes étapes pour déployer un service API.
Cependant, j’ai dû surmonter plusieurs défis pour que cela fonctionne.
Notre premier problème et le plus difficile a été d’installer la bibliothèque de transformateurs pour commencer.
Heureusement, il est simple d’installer des packages tiers à utiliser dans Fonctions cloud basées sur Python.
Il vous suffit de créer un fichier requirements.txt standard fichier comme ceci:
%%writefile requirements.txt
transformers==2.0.7Malheureusement, cela échoue car les transformateurs nécessitent Pytorch ou Tensorflow. Ils sont tous deux installés par défaut dans Google Colab, mais doivent être spécifiés pour l’environnement Cloud Functions.
Par défaut, Transformers utilise Pytorch, et quand je l’ai ajouté en tant qu’exigence, il a généré une erreur qui m’a amené à cet utile Fil de débordement de pile.
Je l’ai fait fonctionner avec ce fichier required.txt mis à jour.
%%writefile requirements.txt
https://download.pytorch.org/whl/cpu/torch-1.0.1.post2-cp37-cp37m-linux_x86_64.whl
transformers==2.0.7Le prochain défi était les énormes besoins en mémoire des modèles et les limitations des fonctions cloud.
J’ai d’abord testé des fonctions en utilisant des pipelines plus simples comme celui de NER, NER signifie Reconnaissance d’entité de nom.
Je le teste d’abord dans le cahier Colab.
from transformers import pipeline
nlp_token_class = None
def ner_get(request):
global nlp_token_class
#run once
if nlp_token_class is None:
nlp_token_class = pipeline('ner')
result = nlp_token_class('Hugging Face is a French company based in New-York.')
return resultJ’ai reçu cette réponse de panne.
[{'entity': 'I-ORG', 'score': 0.9970937967300415, 'word': 'Hu'},
{'entity': 'I-ORG', 'score': 0.9345749020576477, 'word': '##gging'},
{'entity': 'I-ORG', 'score': 0.9787060022354126, 'word': 'Face'},
{'entity': 'I-MISC', 'score': 0.9981995820999146, 'word': 'French'},
{'entity': 'I-LOC', 'score': 0.9983047246932983, 'word': 'New'},
{'entity': 'I-LOC', 'score': 0.8913459181785583, 'word': '-'},
{'entity': 'I-LOC', 'score': 0.9979523420333862, 'word': 'York'}]Ensuite, je peux simplement ajouter un %% writefile main.py pour créer un fichier Python que je peux utiliser pour déployer la fonction.
Quand je examiné les journaux pour savoir pourquoi les appels API ont échoué, j’ai vu que la mémoire requise était un gros problème.
Mais, heureusement, vous pouvez facilement remplacer la limite par défaut de 250 Mo et le délai d’exécution à l’aide de cette commande.
!gcloud functions deploy ner_get --memory 2GiB --timeout 540 --runtime python37 --trigger-http --allow-unauthenticated
Je spécifie essentiellement la mémoire maximale de 2 Go et le délai d’exécution de 9 minutes pour permettre le téléchargement initial du modèle, qui peut être un gigaoctet de transfert.
Une astuce que j’utilise pour accélérer les appels ultérieurs vers la même fonction cloud consiste à mettre en cache le modèle téléchargé en mémoire à l’aide d’une variable globale et en vérifiant si elle existe avant de recréer le pipeline.
Après avoir testé les fonctions BART et T5 et réglé avec un petit modèle T5 qui correspond bien aux exigences de mémoire et de délai d’attente des fonctions cloud.
Voici le code de cette fonction.
%%writefile main.py
from transformers import pipeline
nlp_t5 = None
def t5_get(request):
global nlp_t5
#run once
if nlp_t5 is None:
nlp_t5 = pipeline('summarization', model="t5-small", tokenizer="t5-small")
TEXT_TO_SUMMARIZE = """
New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York...
"""
result = nlp_t5(TEXT_TO_SUMMARIZE)
return result[0]["summary_text"]Et voici le code pour le déployer.
!gcloud functions deploy t5_get --memory 2GiB --timeout 540 --runtime python37 --trigger-http --allow-unauthenticatedUn problème avec cette fonction est que le texte à résumer est codé en dur.
Mais nous pouvons facilement résoudre ce problème avec les modifications suivantes.
%%writefile main.py
from transformers import pipeline
nlp_t5 = None
def t5_post(request):
global nlp_t5
#run once
if nlp_t5 is None:
#small model to avoid memory issue
nlp_t5 = pipeline('summarization', model="t5-small", tokenizer="t5-small")
#Get text to summarize from POST request
content_type = request.headers['content-type']
if content_type == 'application/x-www-form-urlencoded':
text = request.form.get('text')
result = nlp_t5(text)
return result[0]["summary_text"]
else:
raise ValueError("Unknown content type: {}".format(content_type))
return "Failure"Je m’assure simplement que le type de contenu est formulaire encodé en URLet lisez le paramètre texte à partir des données du formulaire.
Je peux facilement tester cette fonction dans Colab en utilisant le code suivant.
import requests
url = "https://us-central1-seo-sheets.cloudfunctions.net/hello_post"
data = {"text": text[:100]}
requests.post(url, data).textComme tout fonctionne comme prévu, je peux travailler à ce que cela fonctionne dans Google Sheets.
Appeler notre service de synthèse de texte à partir de Google Sheets
J’ai introduit Apps Script dans mon colonne précédente et cela donne vraiment des super pouvoirs à Google Sheets.
J’ai pu apporter des modifications mineures à la fonction que j’ai créée pour la rendre utilisable pour la synthèse de texte.
function getSummary(text){
payload = `text=${text}`;
payload = encodeURI(payload);
console.log(payload);
var url = "https://xxx.cloudfunctions.net/t5_post";
var options = {
"method" : "POST",
"contentType" : "application/x-www-form-urlencoded",
"payload" : payload,
'muteHttpExceptions': true
};
var response = UrlFetchApp.fetch(url, options);
var result = response.getContentText();
console.log(result);
return result;
}C’est tout.
J’ai changé le nom de la variable d’entrée et l’URL de l’API.
Le reste est le même que je dois soumettre une demande POST avec les données du formulaire.
Nous effectuons des tests et vérifions journaux de la console pour vous assurer que tout fonctionne comme prévu.
Cela fait.
Une grosse limitation dans Apps Script est que les fonctions personnalisées ne peuvent pas s’exécuter pendant plus de 30 secondes.
Dans la pratique, cela signifie que je peux résumer le texte s’il contient moins de 1 200 caractères, alors qu’en Colab / Python j’ai testé des articles complets avec plus de 10 000 caractères.
Une approche alternative qui devrait mieux fonctionner pour un texte plus long consiste à mettre à jour la feuille Google à partir du code Python comme je l’ai fait dans Cet article.
Gratter le contenu de la page à partir de Google Sheets
Voici quelques exemples du code de travail complet dans Sheets.

Maintenant que nous pouvons résumer le contenu du texte, voyons comment l’extraire directement des pages Web publiques.
Google Sheets comprend une fonction puissante pour cela appelé IMPORTXML.
Nous avons juste besoin de fournir l’URL et un Sélecteur XPath qui identifie le contenu que nous voulons extraire.
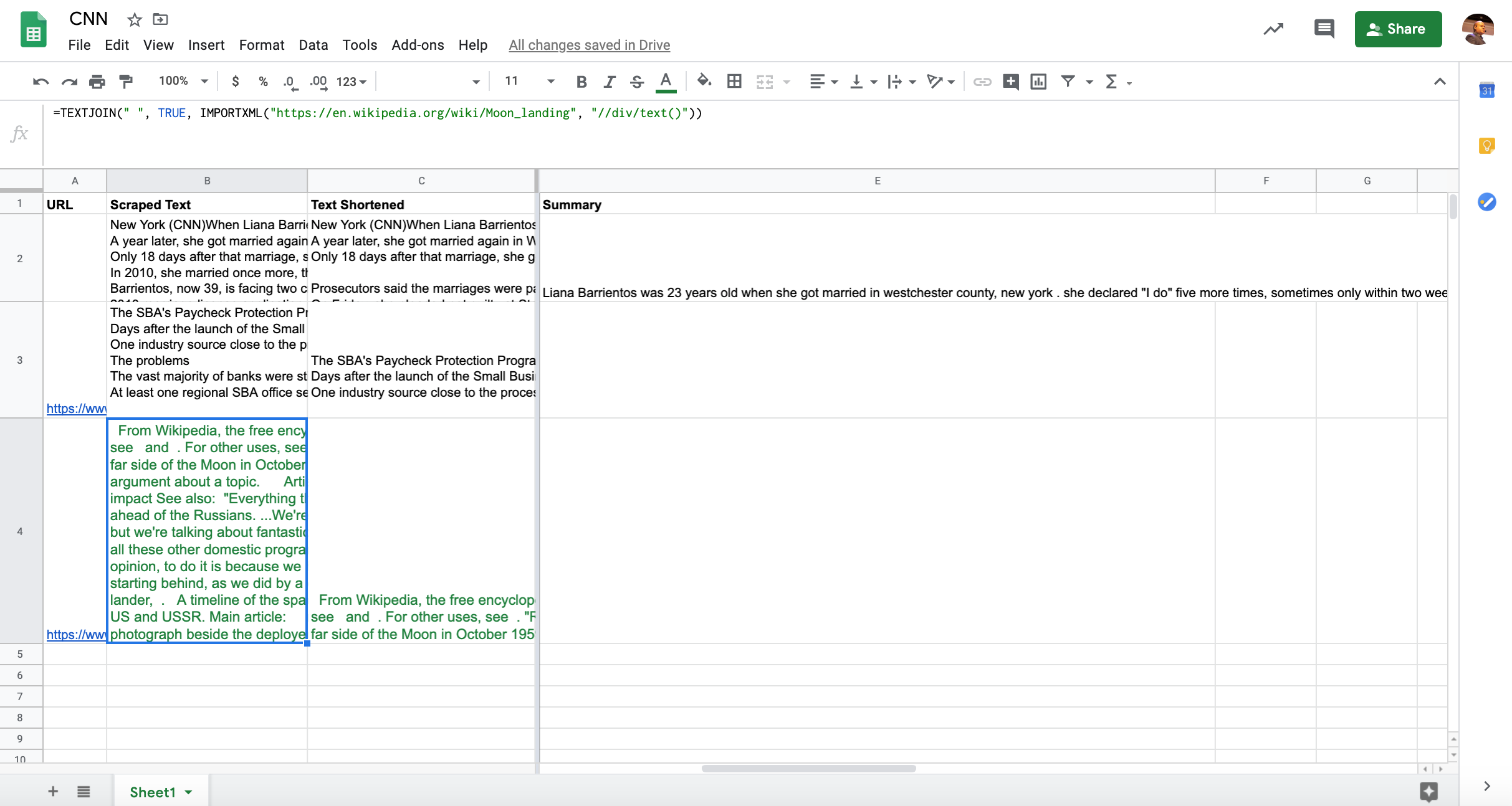
Voici le code pour extraire le contenu d’une page Wikipedia.
=IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//div/text()")J’ai utilisé un sélecteur générique pour capturer tout le texte à l’intérieur des DIV.
N’hésitez pas à jouer avec différents sélecteurs qui correspondent au contenu de votre page cible.
Bien que nous puissions obtenir le contenu de la page, il se décompose sur plusieurs lignes. Nous pouvons résoudre ce problème avec une autre fonction, TEXTJOIN.
=TEXTJOIN(" ", TRUE, IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//div/text()"))Indexation rapide de nos nouvelles descriptions et titres de métadonnées dans Bing
Alors, comment savoir si ces nouveaux extraits de recherche fonctionnent mieux que ceux écrits manuellement ou par rapport à l’absence de métadonnées?
Un moyen infaillible d’apprendre est d’exécuter un test en direct.
Dans ce cas, il est extrêmement important que nos modifications soient indexées rapidement.
J’ai expliqué comment procéder dans Google en automatiser l’outil d’inspection d’URL.
Cette approche nous limite à quelques centaines de pages.
Une meilleure alternative est d’utiliser le génial API d’indexation rapide Bing car nous pouvons demander l’indexation de jusqu’à 10 000 URL!
À quel point cela est cool?
Comme nous serions principalement intéressés à mesurer le CTR, notre hypothèse est que si nous obtenons un CTR plus élevé dans Bing, la même chose se produira probablement dans Google et dans d’autres moteurs de recherche.
Un service permettant aux éditeurs d’obtenir des URL indexées instantanément dans Bing et de commencer à se classer en quelques minutes mérite d’être pris en considération. C’est comme de l’argent gratuit, pourquoi ne le prendrait-on pas?@sejournal @bing @BingWMC https://t.co/a5HkIpbxHI
– Roger Montti (@martinibuster) 20 mars 2020
Je dois être d’accord avec Roger. Voici le code pour le faire.
api_key = "xxx" # Get your own API key from this URL https://www.bing.com/webmaster/home/api
import requests
def submit_to_bing(request):
global api_key
api_url=f"https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey={api_key}"
print(api_url)
#Replace for your site
url_list = [
"https://www.domain.com/page1.html", "https://www.domain.com/page2.html"]
data = {
"siteUrl": "http://www.domain.com",
"urlList": url_list
}
r = requests.post(api_url, json=data)
if r.status_code == 200:
return r.json()
else:
return r.status_codeSi la soumission réussit, vous devez vous attendre à cette réponse.
{'d': None}Nous pouvons ensuite créer une autre fonction cloud en l’ajoutant à notre main.py fichier et en utilisant la commande deploy comme précédemment.
Test de nos extraits de code générés dans Cloudflare
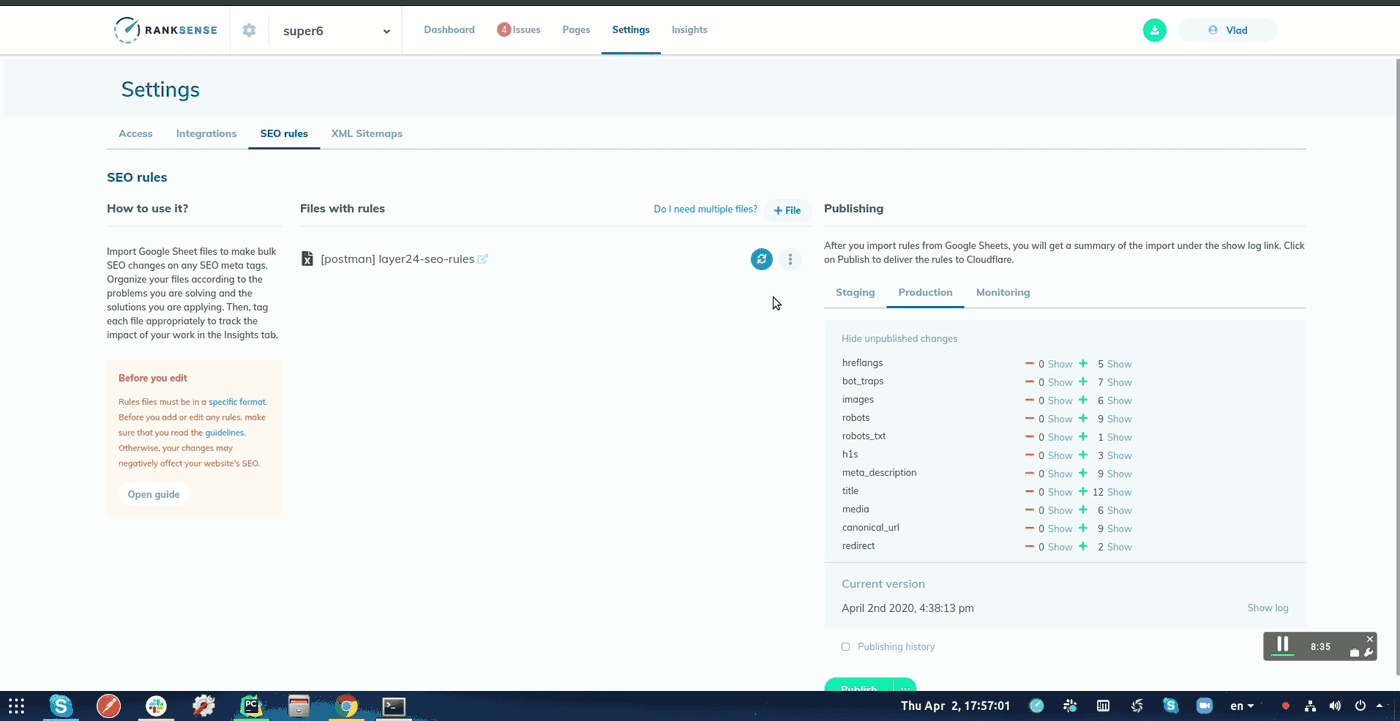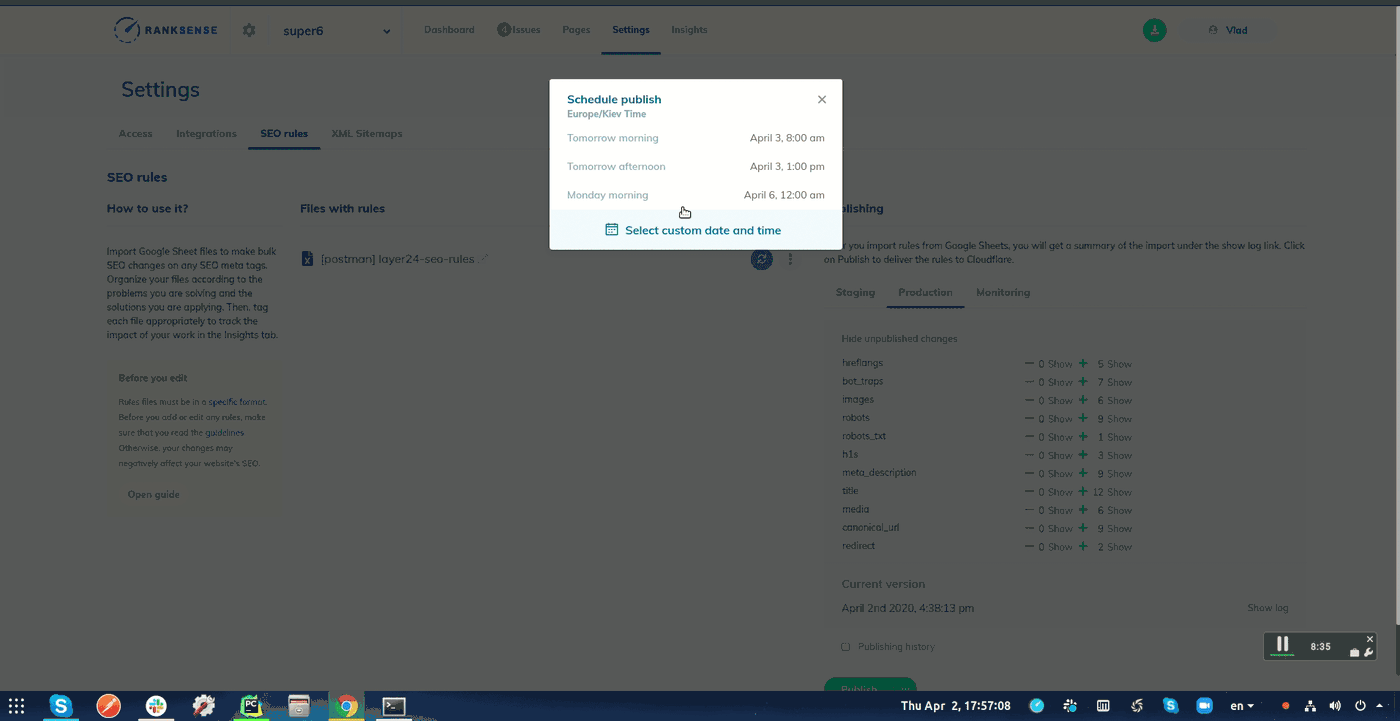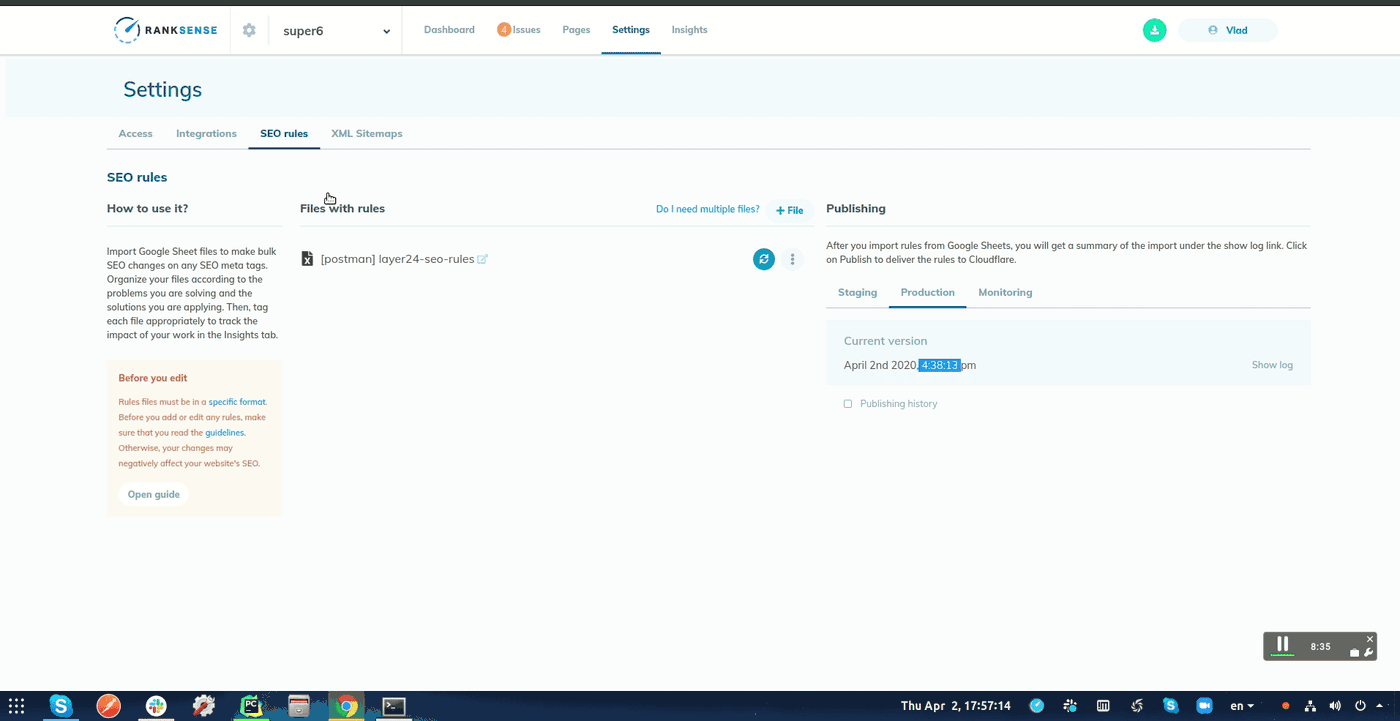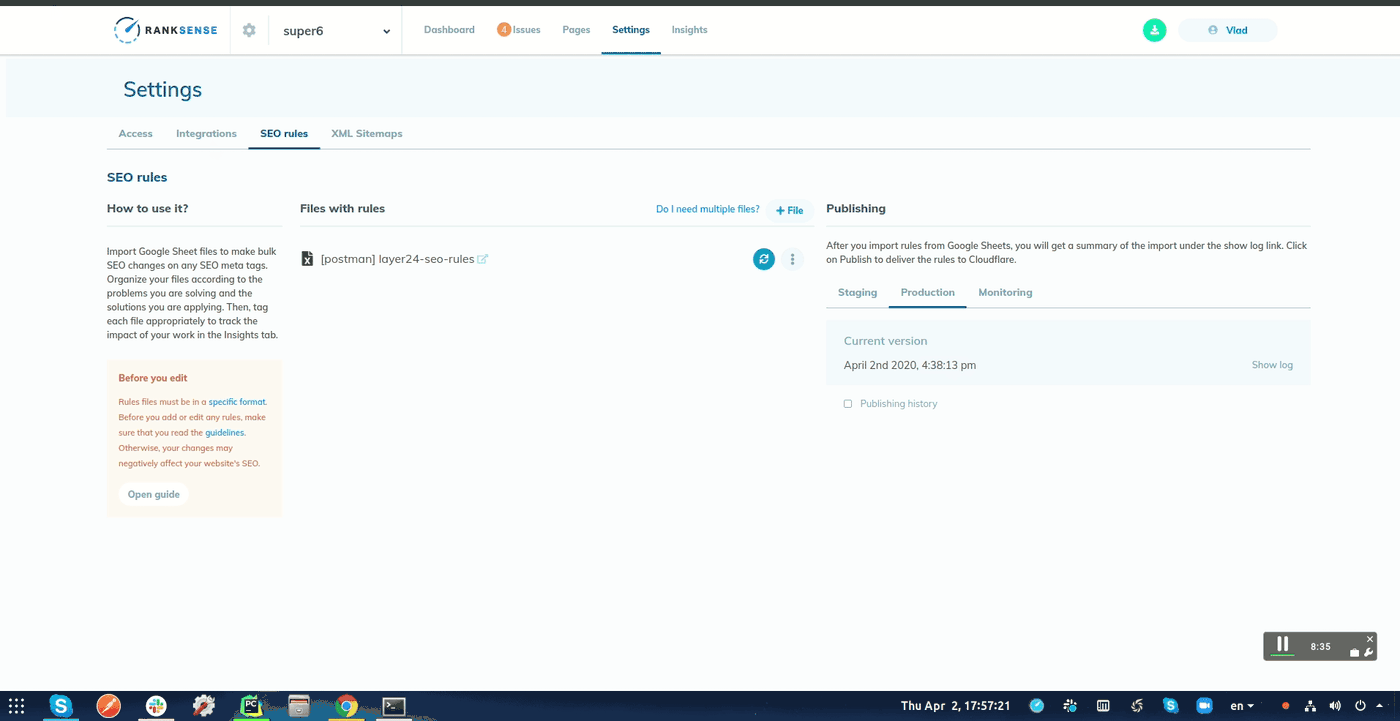
Enfin, si votre site utilise le Cloudflare CDN, vous pouvez utiliser le Application RankSense pour exécuter ces modifications en tant qu’expériences avant de les déployer sur le site.
Copiez simplement l’URL et les colonnes de résumé du texte dans une nouvelle feuille Google et importez-les dans l’outil.

Lorsque vous publiez le test, vous pouvez choisir de planifier la modification et spécifier un webhook URL.
Une URL de webhook permet aux applications et services de communiquer entre eux dans des workflows automatisés.
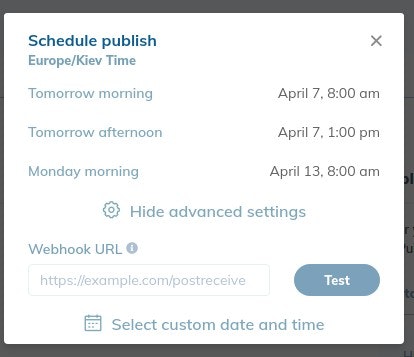

Copiez et collez l’URL de la fonction cloud d’indexation Bing. RankSense l’appellera automatiquement 15 minutes après la propagation des modifications dans Cloudflare.
Ressources pour en savoir plus
Voici des liens vers des ressources qui ont été vraiment utiles lors de la recherche de cette pièce.
Crédits d’image
Toutes les captures d’écran prises par l’auteur, avril 2020



Commentaires récents