
Une fuite de Google Memo admet la défaite de l’IA open source
Une note de service de Google divulguée offre un résumé point par point des raisons pour lesquelles Google perd face à l’IA open source et suggère un chemin de retour vers la domination et la propriété de la plate-forme.
Le mémo s’ouvre en reconnaissant que leur concurrent n’a jamais été OpenAI et allait toujours être Open Source.
Impossible de rivaliser avec l’open source
De plus, ils admettent qu’ils ne sont en aucun cas positionnés pour concurrencer l’open source, reconnaissant qu’ils ont déjà perdu la lutte pour la domination de l’IA.
Ils ont écrit:
«Nous avons beaucoup regardé par-dessus nos épaules à OpenAI. Qui franchira le prochain cap ? Quelle sera la prochaine étape ?
Mais la vérité inconfortable est que nous ne sommes pas positionnés pour gagner cette course aux armements et OpenAI non plus. Pendant que nous nous disputions, une troisième faction mangeait tranquillement notre déjeuner.
Je parle, bien sûr, de l’open source.
En clair, ils nous lapent. Les choses que nous considérons comme des « problèmes ouverts majeurs » sont résolues et entre les mains des gens aujourd’hui. »
La majeure partie de la note est consacrée à la description de la façon dont Google est surpassé par l’open source.
Et même si Google a un léger avantage sur l’open source, l’auteur du mémo reconnaît qu’il s’esquive et ne reviendra jamais.
L’auto-analyse des cartes métaphoriques qu’ils se sont distribuées est considérablement pessimiste :
« Bien que nos modèles conservent un léger avantage en termes de qualité, l’écart se réduit étonnamment rapidement.
Les modèles open source sont plus rapides, plus personnalisables, plus privés et livre pour livre plus performants.
Ils font des choses avec des paramètres de 100 et 13 milliards de dollars avec lesquels nous luttons à 10 millions de dollars et 540 milliards de dollars.
Et ils le font en semaines, pas en mois.
La grande taille du modèle de langue n’est pas un avantage
La réalisation la plus effrayante exprimée dans le mémo est peut-être que la taille de Google n’est plus un avantage.
La taille exorbitante de leurs modèles est désormais considérée comme un inconvénient et non comme l’avantage insurmontable qu’ils pensaient être.
Le mémo divulgué énumère une série d’événements qui signalent que le contrôle de Google (et d’OpenAI) sur l’IA pourrait être rapidement terminé.
Il raconte qu’il y a à peine un mois, en mars 2023, la communauté open source a obtenu un modèle de grand langage de modèle open source divulgué développé par Meta appelé LLaMA.
En quelques jours et semaines, la communauté open source mondiale a développé toutes les pièces de construction nécessaires pour créer des clones Bard et ChatGPT.
Des étapes sophistiquées telles que le réglage des instructions et l’apprentissage par renforcement à partir de la rétroaction humaine (RLHF) ont été rapidement reproduites par la communauté open source mondiale, à moindre coût.
- Réglage des instructions
Un processus d’ajustement d’un modèle de langage pour lui faire faire quelque chose de spécifique pour lequel il n’a pas été initialement formé. - Apprentissage par renforcement à partir de la rétroaction humaine (RLHF)
Une technique où les humains évaluent une sortie de modèle de langage afin qu’elle apprenne quelles sorties sont satisfaisantes pour les humains.
RLHF est la technique utilisée par OpenAI pour créer InstructGPT, qui est un modèle sous-jacent à ChatGPT et permet aux modèles GPT-3.5 et GPT-4 de prendre des instructions et d’accomplir des tâches.
RLHF est le feu que l’open source a tiré de
L’ampleur des peurs de l’open source Google
Ce qui effraie Google en particulier, c’est le fait que le mouvement Open Source est capable de faire évoluer ses projets d’une manière que la source fermée ne peut pas.
L’ensemble de données de questions et réponses utilisé pour créer le clone open source de ChatGPT, Dolly 2.0, a été entièrement créé par des milliers d’employés bénévoles.
Google et OpenAI se sont appuyés en partie sur les questions et réponses extraites de sites comme Reddit.
L’ensemble de données de questions-réponses open source créé par Databricks est prétendu être de meilleure qualité car les humains qui ont contribué à sa création étaient des professionnels et les réponses qu’ils ont fournies étaient plus longues et plus substantielles que ce que l’on trouve dans un ensemble de données de questions et réponses typique extrait d’un tribune publique.
La note divulguée a observé:
« Début mars, la communauté open source a mis la main sur son premier modèle de base vraiment performant, car le LLaMA de Meta a été divulgué au public.
Il n’y avait pas d’instruction ou de réglage de conversation, et pas de RLHF.
Néanmoins, la communauté a immédiatement compris la signification de ce qui leur avait été donné.
Une formidable vague d’innovation a suivi, avec quelques jours seulement entre les développements majeurs…
Nous y sommes, à peine un mois plus tard, et il existe des variantes avec réglage des instructions, quantification, améliorations de la qualité, évaluations humaines, multimodalité, RLHF, etc., etc., dont beaucoup s’appuient les unes sur les autres.
Plus important encore, ils ont résolu le problème de mise à l’échelle dans la mesure où n’importe qui peut bricoler.
Beaucoup de nouvelles idées viennent de gens ordinaires.
La barrière à l’entrée pour la formation et l’expérimentation est passée de la production totale d’un grand organisme de recherche à une personne, une soirée et un ordinateur portable costaud.
En d’autres termes, ce qui a pris des mois et des années à Google et à OpenAI pour s’entraîner et se construire n’a pris que quelques jours à la communauté open source.
Cela doit être un scénario vraiment effrayant pour Google.
C’est l’une des raisons pour lesquelles j’ai tant écrit sur le mouvement de l’IA open source, car il semble vraiment que l’avenir de l’IA générative se situera dans un laps de temps relativement court.
L’open source a historiquement dépassé le open source
Le mémo cite l’expérience récente avec DALL-E d’OpenAI, le modèle d’apprentissage en profondeur utilisé pour créer des images par rapport à la diffusion stable open source comme un signe avant-coureur de ce qui arrive actuellement à l’IA générative comme Bard et ChatGPT.
Dall-e a été publié par OpenAI en janvier 2021. Stable Diffusion, la version open source, est sortie un an et demi plus tard en août 2022 et en quelques semaines a dépassé la popularité de Dall-E.
Ce graphique chronologique montre à quelle vitesse Stable Diffusion a dépassé Dall-E :
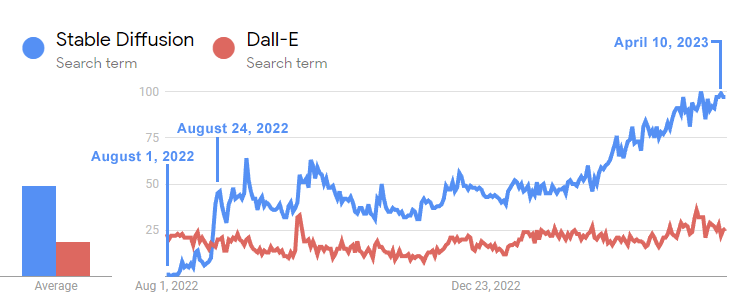
La chronologie Google Trends ci-dessus montre à quel point l’intérêt pour le modèle open source Stable Diffusion a largement dépassé celui de Dall-E dans les trois semaines suivant sa sortie.
Et bien que Dall-E soit sorti depuis un an et demi, l’intérêt pour Stable Diffusion a continué de monter en flèche de façon exponentielle tandis que Dall-E d’OpenAI est resté stagnant.
La menace existentielle d’événements similaires dépassant Bard (et OpenAI) donne des cauchemars à Google.
Le processus de création du modèle Open Source est supérieur
Un autre facteur qui inquiète les ingénieurs de Google est que le processus de création et d’amélioration des modèles open source est rapide, peu coûteux et se prête parfaitement à une approche collaborative globale commune aux projets open source.
Le mémo observe que de nouvelles techniques telles que LoRA (Low-Rank Adaptation of Large Language Models), permettent d’affiner les modèles de langage en quelques jours à un coût extrêmement faible, le LLM final étant comparable aux LLM extrêmement plus chers. créé par Google et OpenAI.
Un autre avantage est que les ingénieurs open source peuvent s’appuyer sur des travaux antérieurs, itérer, au lieu de devoir repartir de zéro.
Construire de grands modèles de langage avec des milliards de paramètres comme l’ont fait OpenAI et Google n’est plus nécessaire aujourd’hui.
C’est peut-être le point auquel Sam Alton faisait récemment allusion lorsqu’il a récemment déclaré que l’ère des grands modèles de langage massifs était révolue.
L’auteur de la note de Google a opposé l’approche LoRA bon marché et rapide pour créer des LLM à l’approche actuelle de la grande IA.
L’auteur de la note réfléchit à la lacune de Google :
« En revanche, la formation de modèles géants à partir de zéro non seulement supprime la pré-formation, mais également toutes les améliorations itératives qui ont été apportées en plus. Dans le monde open source, il ne faut pas longtemps avant que ces améliorations ne dominent, ce qui rend un recyclage complet extrêmement coûteux.
Nous devons nous demander si chaque nouvelle application ou idée a vraiment besoin d’un tout nouveau modèle.
… En effet, en termes d’heures-ingénieur, le rythme d’amélioration de ces modèles dépasse largement ce que nous pouvons faire avec nos plus grandes variantes, et les meilleures sont déjà largement indiscernables de ChatGPT.
L’auteur conclut en réalisant que ce qu’ils pensaient être leur avantage, leurs modèles géants et leur coût prohibitif concomitant, était en réalité un inconvénient.
La nature collaborative mondiale de l’Open Source est plus efficace et des ordres de grandeur plus rapides à l’innovation.
Comment un système à source fermée peut-il rivaliser avec la multitude écrasante d’ingénieurs du monde entier ?
L’auteur conclut qu’ils ne peuvent pas rivaliser et que la concurrence directe est, selon eux, une « proposition perdante ».
C’est la crise, la tempête, qui se développe en dehors de Google.
Si vous ne pouvez pas battre l’open source, rejoignez-les
La seule consolation que l’auteur du mémo trouve dans l’open source est que, puisque les innovations open source sont gratuites, Google peut également en profiter.
Enfin, l’auteur conclut que la seule approche ouverte à Google est de posséder la plate-forme de la même manière qu’ils dominent les plates-formes open source Chrome et Android.
Ils soulignent comment Meta bénéficie de la publication de leur grand modèle de langage LLaMA pour la recherche et comment ils ont maintenant des milliers de personnes qui font leur travail gratuitement.
Peut-être que le gros point à retenir de la note de service est que Google pourrait dans un proche avenir essayer de reproduire sa domination open source en publiant ses projets sur une base open source et ainsi posséder la plate-forme.
La note conclut que l’open source est l’option la plus viable :
« Google devrait s’établir comme un leader dans la communauté open source, en prenant les devants en coopérant avec, plutôt qu’en ignorant, la conversation plus large.
Cela signifie probablement prendre des mesures inconfortables, comme publier les poids des modèles pour les petites variantes d’ULM. Cela signifie nécessairement renoncer à un certain contrôle sur nos modèles.
Mais ce compromis est inévitable.
Nous ne pouvons pas espérer à la fois stimuler l’innovation et la contrôler.
L’open source s’en va avec le feu de l’IA
La semaine dernière, j’ai fait une allusion au mythe grec du héros humain Prométhée volant le feu aux dieux sur le mont Olympe, opposant l’open source à Prométhée aux « dieux olympiens » de Google et OpenAI :
je tweeté:
« Alors que Google, Microsoft et Open AI se chamaillent et se tournent le dos, l’Open Source marche-t-il avec leur feu ? »
La fuite du mémo de Google confirme cette observation mais elle pointe également vers un possible changement de stratégie chez Google pour rejoindre le mouvement open source et ainsi le coopter et le dominer de la même manière qu’ils l’ont fait avec Chrome et Android.
Lisez le mémo Google divulgué ici :



Commentaires récents