
Une introduction pratique à l’apprentissage automatique pour les professionnels du référencement
La liste des tâches SEO époustouflantes pouvant être automatisées continue de s’allonger et je suis impatient de voir davantage d’applications d’automatisation partagées dans la communauté.
Impliquons-nous!
Compte tenu de l’accueil positif de ma pratique introduction à la colonne Python et l’importance croissante des compétences d’apprentissage automatique, j’ai décidé d’écrire cette pièce d’apprentissage automatique, que j’ai essayé de rendre super facile à suivre.
J’ai codé un simple à suivre Bloc-notes Google Colab que vous pouvez utiliser pour produire un ensemble de données de formation personnalisé. Cet ensemble de données nous aidera à construire un modèle prédictif du CTR.
Cependant, au lieu d’utiliser notre modèle pour prédire le CTR, nous l’utiliserons pour savoir si l’ajout de mots clés aux balises de titre prédit le succès.
J’envisage de réussir si nos pages génèrent davantage de clics de recherche naturels.
Les données de formation proviendront de la Google Search Console et les balises de titre (et les méta descriptions) du grattage des pages.
Voici notre plan technique pour générer l’ensemble de données de formation:
- Extrait: Notre code se connectera à Google Search Console et récupérera nos données de formation initiales.
- Transformer: Ensuite, nous allons récupérer les titres des pages et les méta descriptions et calculer si les requêtes sont dans les titres.
- Charge: Enfin, nous allons exporter notre jeu de données avec toutes les fonctionnalités et l’importer dans le système ML.
Dans la plupart des projets d’apprentissage automatique, vous passerez la majeure partie de votre temps à assembler l’ensemble de données de formation.
Le travail réel d’apprentissage automatique nécessite beaucoup moins d’efforts mais nécessite une compréhension claire des principes fondamentaux.
Afin de garder la partie d’apprentissage automatique super simple, nous allons prendre nos données et les brancher sur BigML, un ensemble d’outils d’apprentissage automatique «faites-le pour vous».
C’est ce que j’ai appris lorsque j’ai terminé ce tutoriel en utilisant les données d’un de mes clients (les vôtres peuvent être différentes).

Après la position du mot clé et les impressions de recherche, la présence de la requête dans le titre joue un rôle prédictif lorsque vous essayez d’augmenter les clics de recherche naturels.
Voyons comment j’ai effectué cette analyse à l’aide de l’apprentissage automatique.
Extraire, transformer et charger
Un processus très courant dans le pipeline d’apprentissage automatique est appelé extraire, transformer, charger.
Traditionnellement, c’était l’idée de déplacer des données d’une base de données à une autre, mais dans l’apprentissage automatique, vous disposez rarement des données de formation source au format attendu par les modèles.
De nombreuses tâches liées au machine learning sont automatisées, mais je m’attends à ce que l’expertise du domaine sur le type de données permettant de bonnes prévisions reste une compétence précieuse.
En tant que SEO, apprendre à créer des ensembles de données de formation personnalisés est probablement la première chose dont vous avez besoin pour investir du temps dans l’apprentissage et la maîtrise.
Les sources de données publiques et génériques ne sont pas aussi bonnes que celles que vous pouvez créer et gérer vous-même.
Exécution du bloc-notes Colab
D’abord, faites un copie du cahier et créez une feuille de calcul vide que nous utiliserons pour remplir l’ensemble de données de formation.
Vous devez fournir trois éléments:
- Le nom de la feuille de calcul.
- URL du site Web dans la Search Console.
- Un fichier d’autorisation nommé client_id.json.
Permettez-moi de décrire les étapes à suivre pour produire le client_id.json fichier.
Tout d’abord, il existe une configuration pour télécharger un fichier client_id.json que notre code Python peut utiliser pour se connecter en toute sécurité à Google Search Console.
Tout d’abord, assurez-vous d’exécuter la cellule avec le formulaire contenant les valeurs d’entrée dans le bloc-notes.
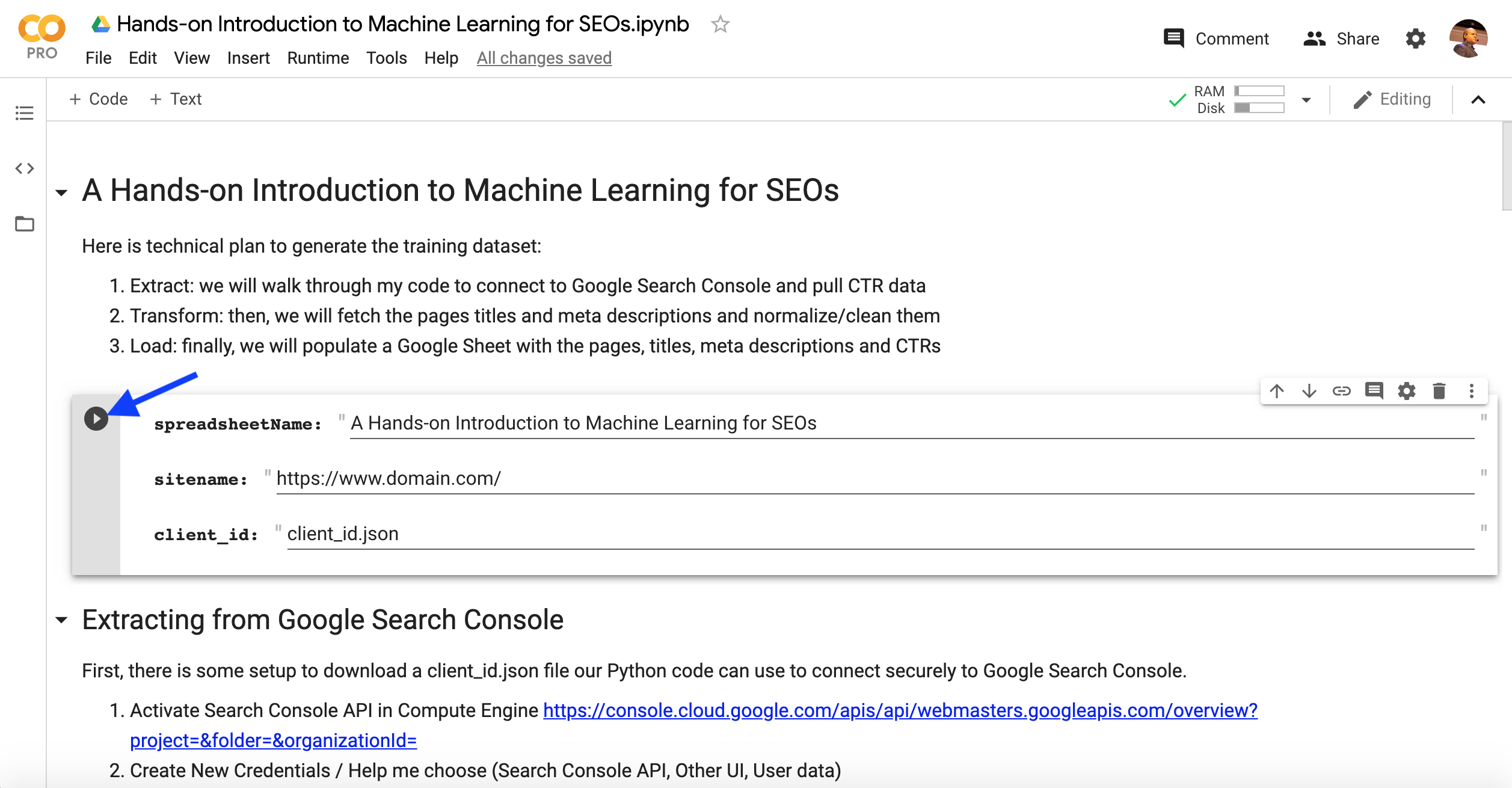

Le code suivant dans le bloc-notes vous invite à télécharger le fichier client_id.json depuis votre ordinateur.
#Next, we need to upload the file
from google.colab import files
files.upload()Vous pouvez cliquer sur Runtime> Exécuter après dans la ligne après avoir téléchargé le fichier client_id.json (n’oubliez pas d’exécuter le formulaire en haut en premier, afin que les valeurs saisies soient capturées).
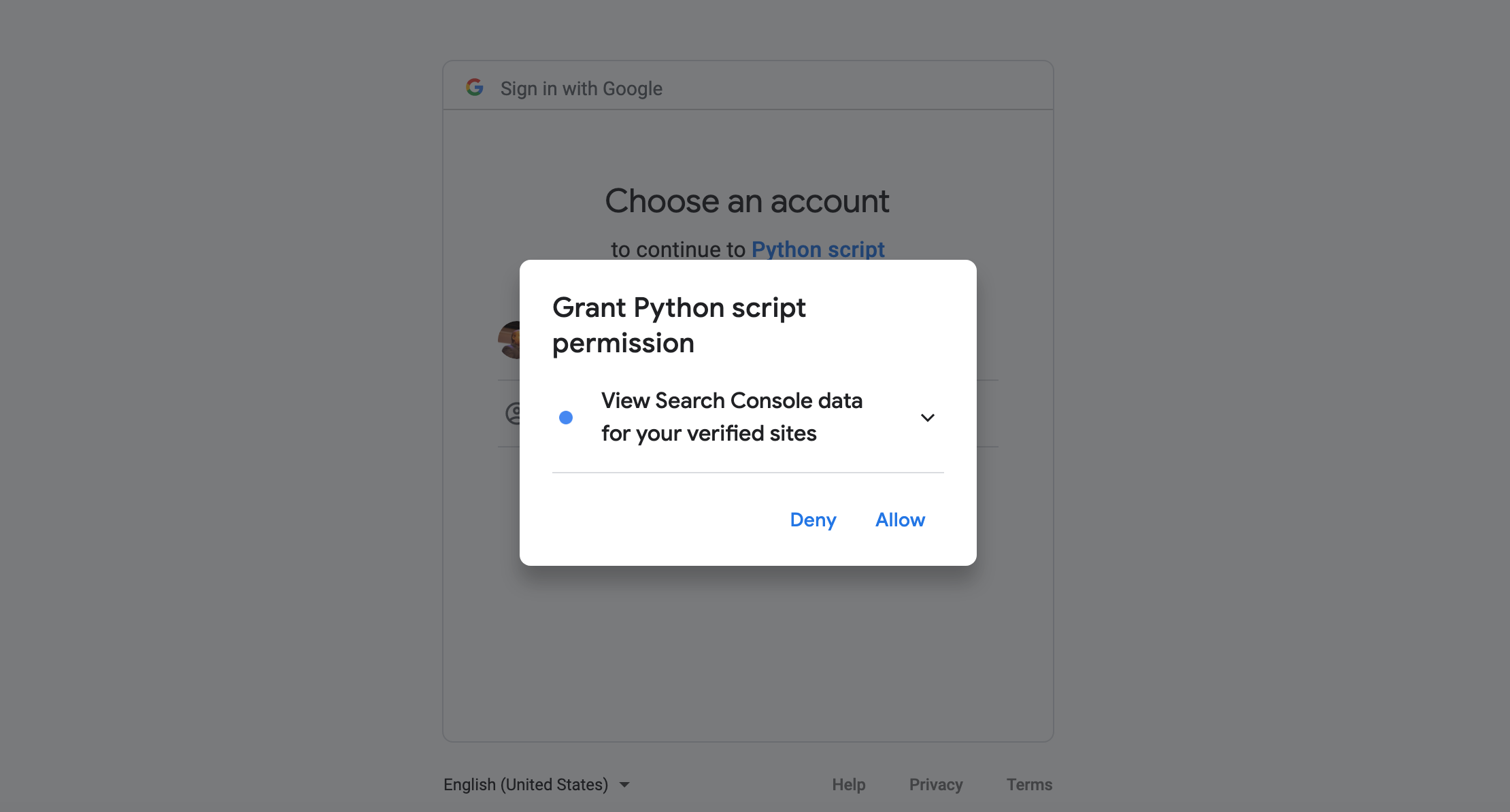

Vous serez invité à autoriser l’accès à la Search Console.
Veuillez copier et coller le code d’autorisation dans le carnet.
Il va y avoir une deuxième invite, cela nous donnera accès à la feuille de calcul vierge.
Après avoir exécuté toutes les cellules, vous devriez vous retrouver avec un jeu de données d’entraînement personnalisé dans la feuille de calcul vierge comme celle-ci.
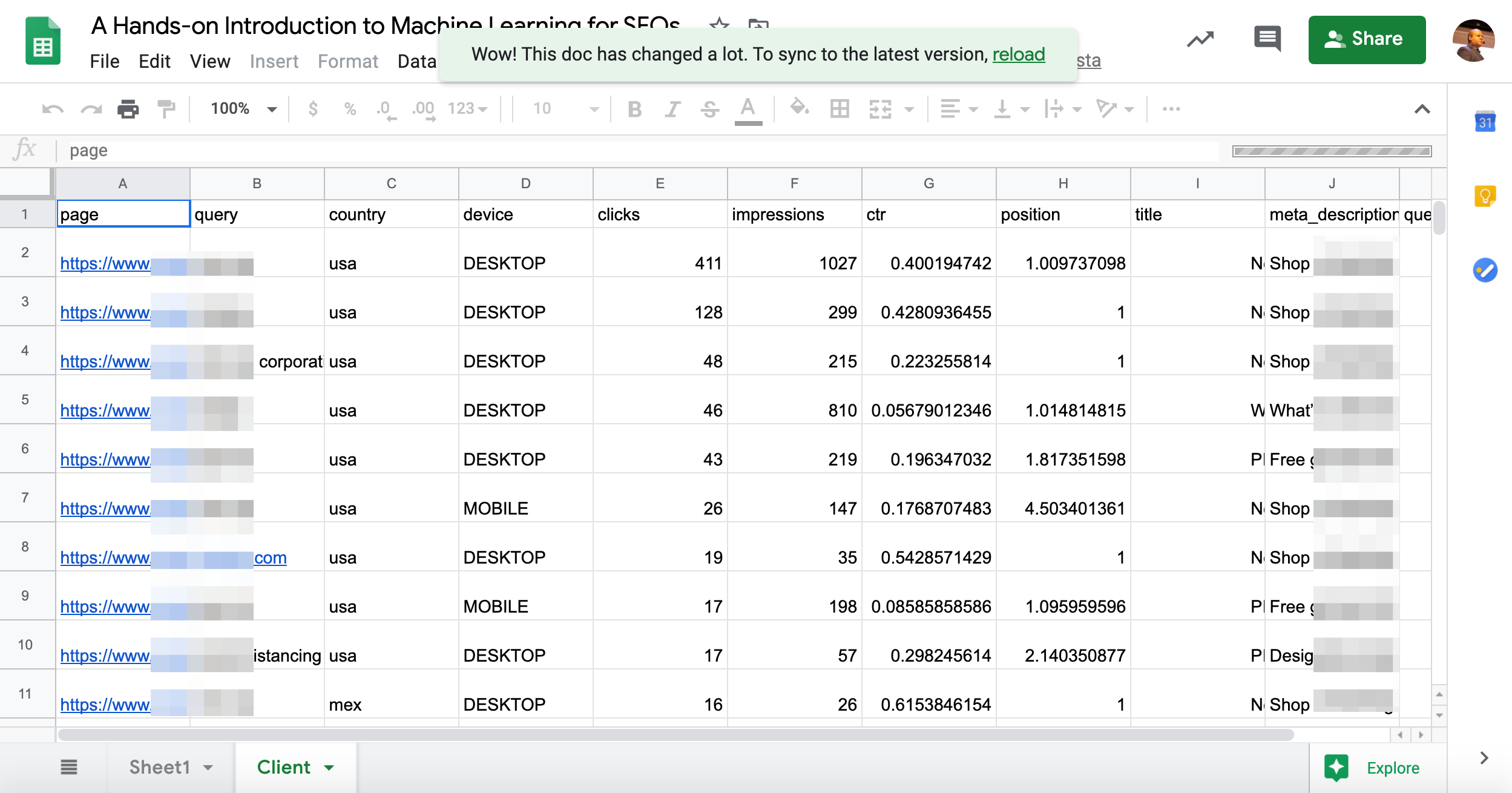

Prenons notre ensemble de données de formation sur BigML et voyons ce que nous allons apprendre.
Nous allons passer en revue une partie du code dans le bloc-notes après la partie BigML.
Former le modèle prédictif
BigML facilite la création de modèles prédictifs. Vous devez passer par trois phases:
- Importez le fichier de données source (notre feuille Google).
- Créez un ensemble de données qui fonctionnera pour l’apprentissage automatique. Cela comprend la suppression de certaines colonnes et la sélection de la colonne d’objectif que nous allons essayer de prédire.
- Sélectionnez un modèle prédictif pour vous entraîner (nous utiliserons un réseau neuronal profond).
Essayons d’abord une session de formation simple et naïve en utilisant toutes les colonnes de notre jeu de données.
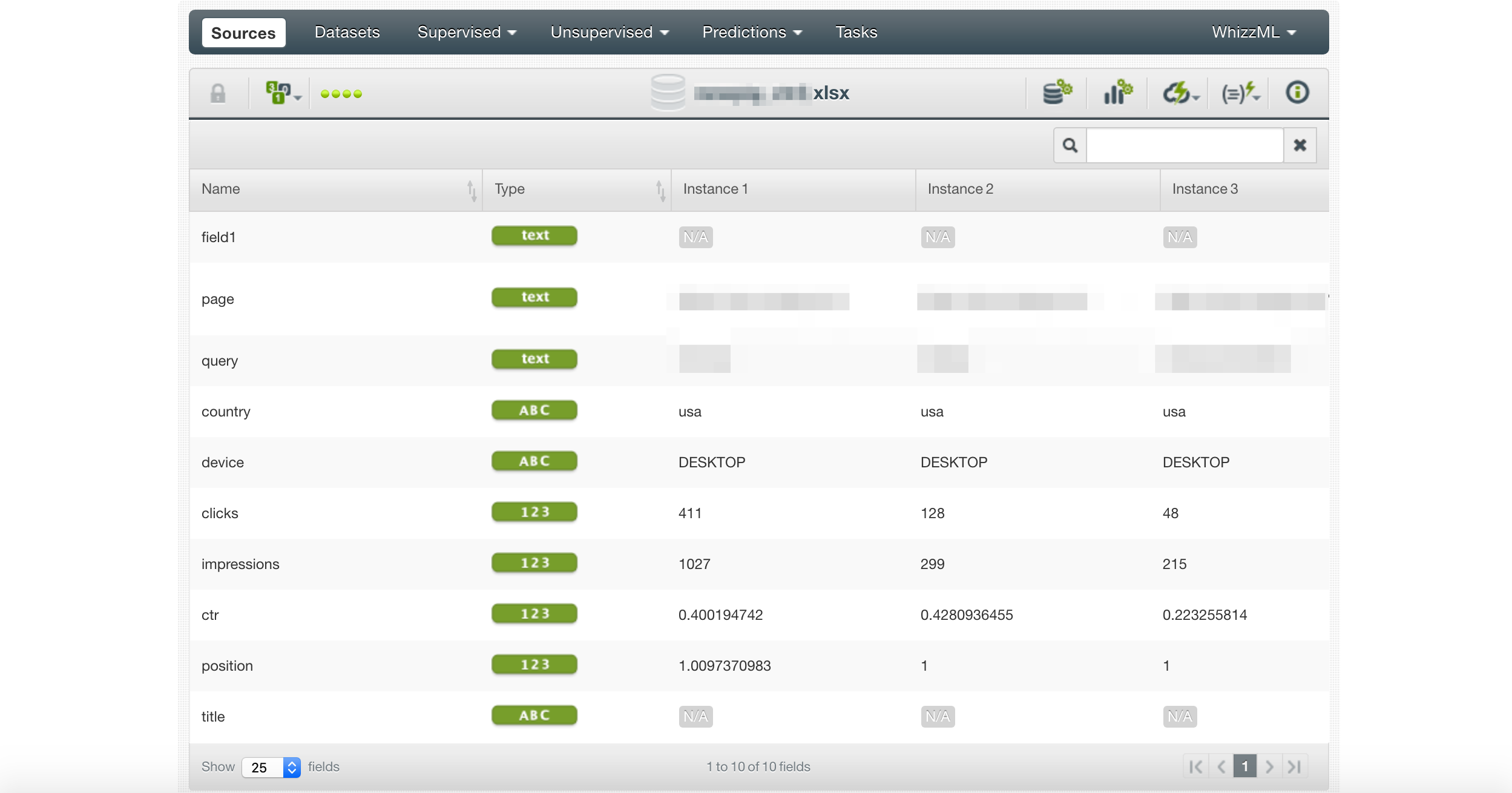

Ici, nous importons la feuille Google que nous avons produite avec le bloc-notes.
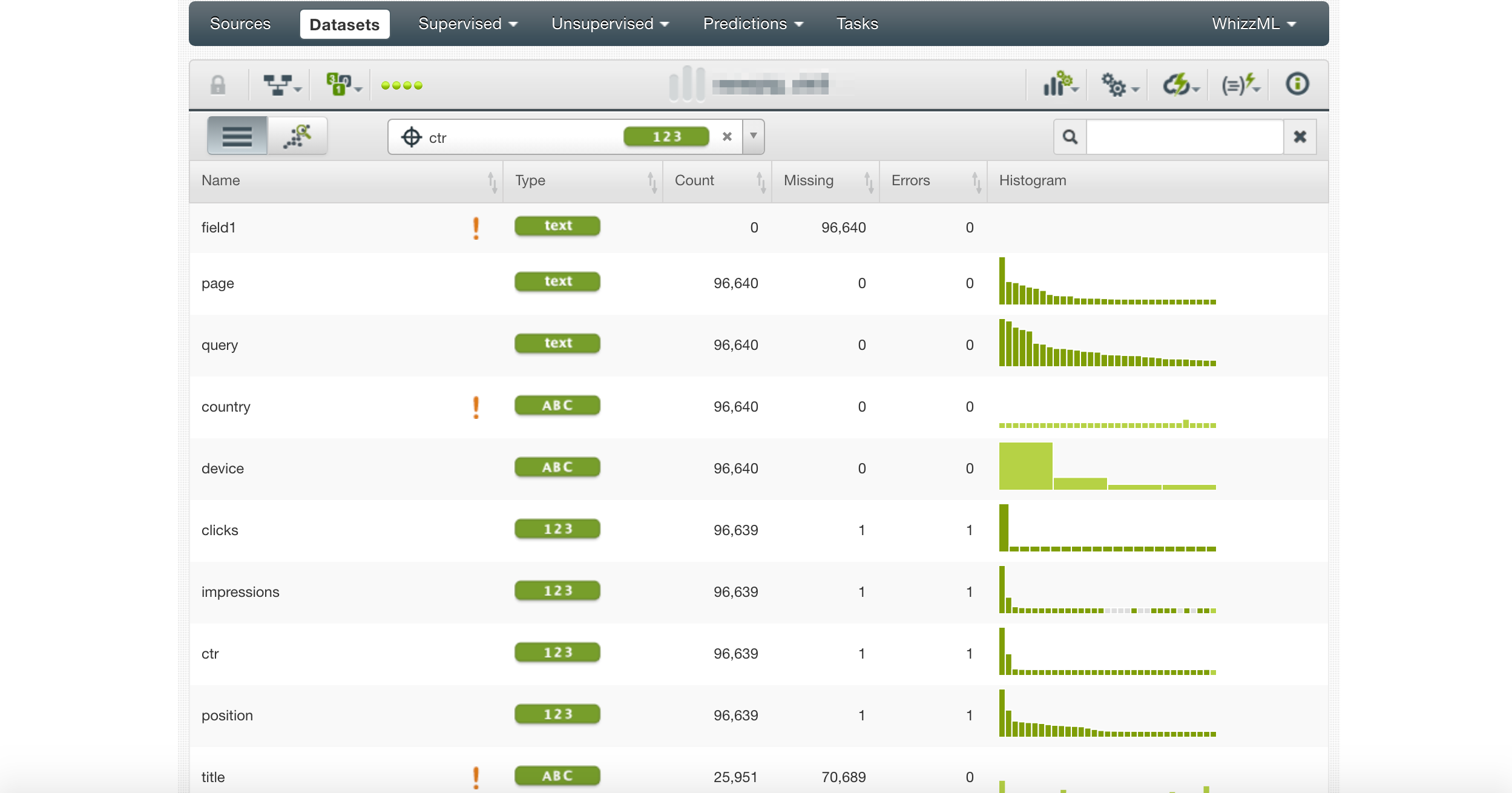

Ensuite, nous créons une source de données et sélectionnons CTR comme cible.

Remarquez les points d’exclamation. Ils mettent en évidence les colonnes qui ne sont pas utiles pour la prédiction.
Nous sélectionnons Deepnet comme modèle à construire et voyons quelles fonctionnalités sont les plus importantes.
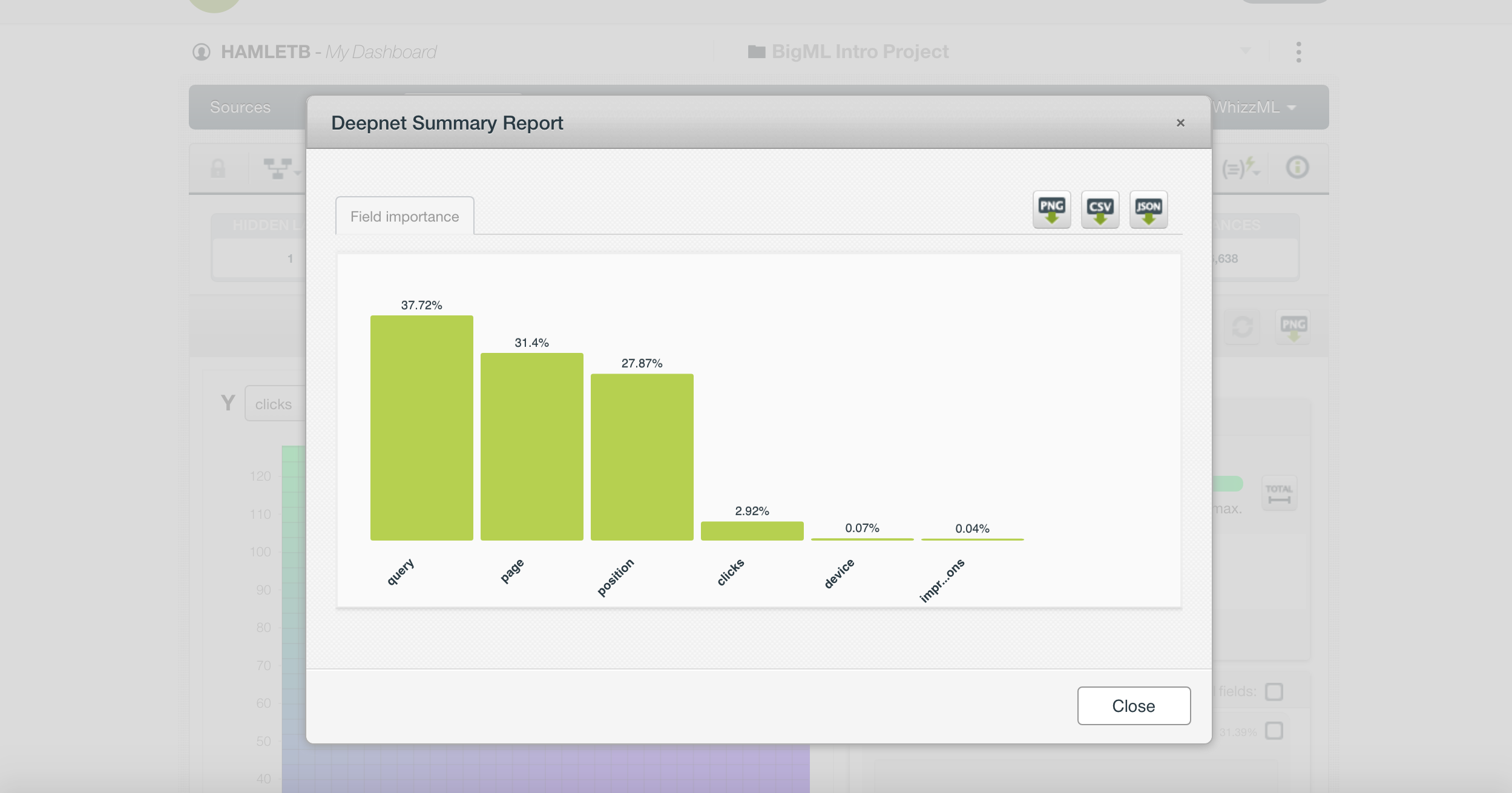

Une chose qui est particulièrement intéressante est que le CTR affiche la requête, la page et la position comme les fonctionnalités les plus importantes.
Cela ne nous dit rien que nous ne savions pas déjà. Il est préférable de supprimer ces colonnes et de réessayer.
Cependant, il existe un autre problème, plus nuancé. Nous incluons le CTR, les clics et les impressions.
Si vous y pensez, le CTR est divisé par le nombre de clics par les impressions, il est donc logique que le modèle trouve cette connexion simple.
Nous devons également exclure le CTR de l’ensemble de formation.
Fonctionnalités indépendantes ou dépendantes
Nous devons inclure uniquement des fonctionnalités indépendantes respectives à notre métrique d’objectif dans notre ensemble de formation.
Voici pourquoi.
Une façon simpliste de penser à un modèle d’apprentissage automatique consiste à imaginer un fonction de régression linéaire dans Excel / Sheets.
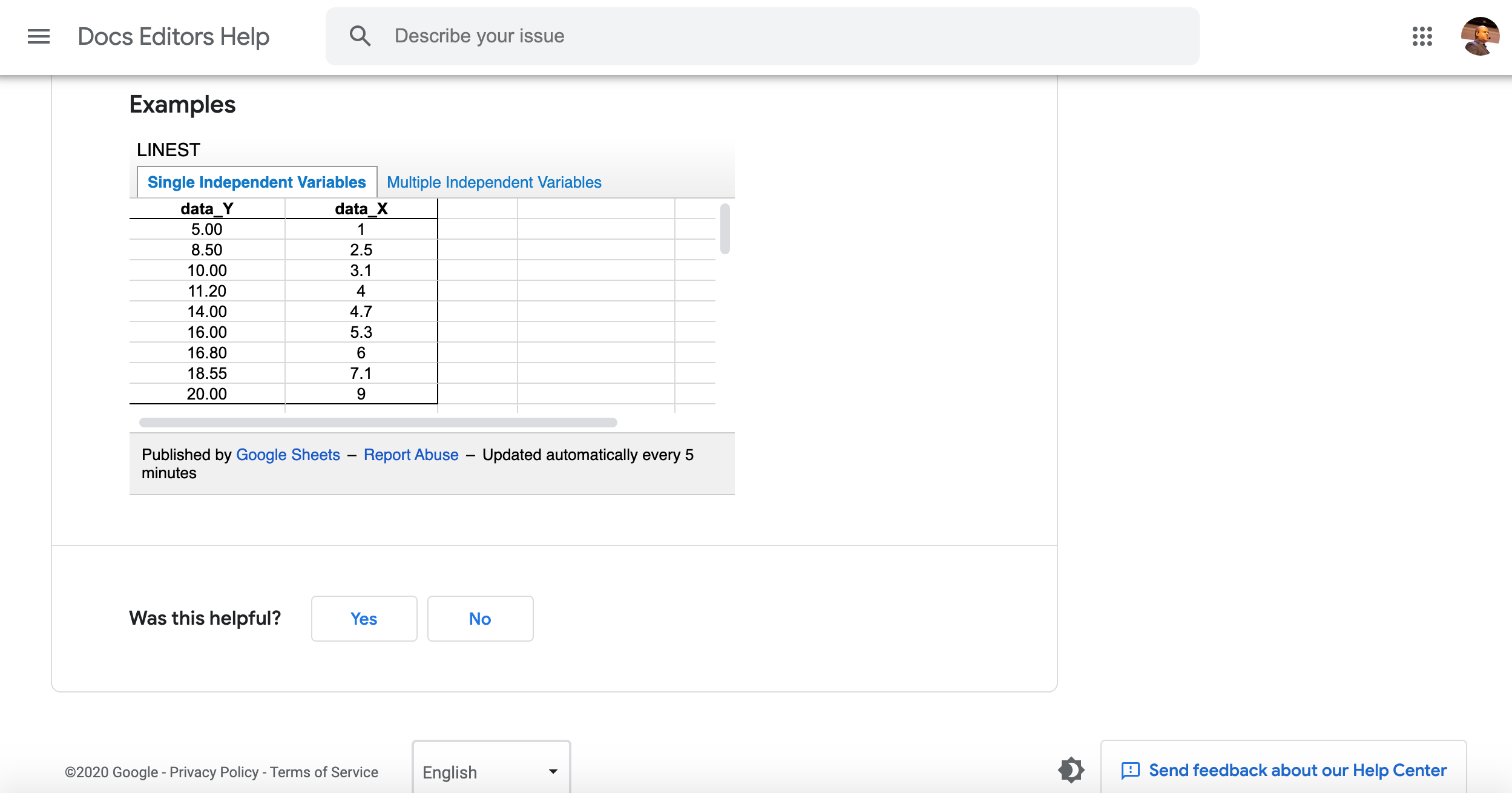

Les valeurs de nos colonnes sont converties en nombres et le but du processus de formation est d’estimer une fonction qui, étant donné une valeur, peut faire une prédiction précise.
Nous essayons de prédire des valeurs Y, des valeurs X données et un ensemble de valeurs Y, X précédemment connues.
X est une variable indépendante et Y est une variable dépendante. Cela dépend des valeurs de X.
Mélanger négligemment les variables indépendantes et dépendantes (comme nous l’avons fait ci-dessus) conduit à des modèles inutiles.
Nous pouvons corriger cela en modifiant la métrique d’objectif en clics et en supprimant la colonne CTR de notre ensemble de données.
Les clics sont indépendants des impressions, car vous avez également besoin du CTR, que nous avons supprimé.
Nous avons également supprimé les colonnes de page et de requête car elles ne sont pas informatives.
Améliorer l’ensemble d’entraînement avec de nouvelles fonctionnalités
Souvent, les fonctionnalités auxquelles vous avez accès ne sont pas assez informatives et vous devez en créer de nouvelles.
C’est là que votre expertise de domaine et vos connaissances Python peuvent faire une grande différence.
Un data scientist travaillant sur un modèle prédictif CTR pourrait ne pas avoir l’expertise SEO pour savoir que les mots clés dans les balises de titre peuvent faire la différence.
Dans le bloc-notes, nous avons ajouté du code pour créer une nouvelle colonne, query_in_title, Cela donne un score de 0 à 100 si le titre inclut la requête recherchée.
Lorsque nous l’avons inclus dans l’ensemble de formation et examiné son importance dans le modèle prédictif (comme le montre l’image ci-dessus), nous avons appris quelque chose de nouveau et de précieux.
Nous pourrions suivre un processus similaire et vérifier l’impact des requêtes dans la méta description, ou le sentiment émotionnel dans le titre et la méta description, etc.
Je trouve que ce type d’exercice est un avantage sous-estimé de la formation de modèles d’apprentissage automatique.
Les machines sont vraiment bonnes pour trouver des modèles invisibles dans les données tant que vous avez l’expertise du domaine pour poser les bonnes questions.
Examinons le code que j’ai utilisé pour générer cette nouvelle colonne.
Ajout de nouvelles fonctionnalités informatives
Vérifier si une requête apparaît dans un titre semble simple, mais il est vraiment nuancé.
Il est possible que la requête ne soit que partiellement incluse.
Nous pouvons effectuer une correspondance partielle en effectuant un recherche floue. Nous le faisons en Python en utilisant la bibliothèque flou.
Voici le code pour cela.
!pip install fuzzywuzzy[speedup]
from fuzzywuzzy import fuzz
#remove empty rows from the data frame
df = df.dropna()
df["query_in_title"] = df.apply(lambda row: fuzz.partial_ratio(row["query"], row["title"]), axis=1)
df[["page", "query", "country", "device", "clicks", "impressions", "position", "query_in_title" ]].to_excel("client.xlsx", index=False)
from google import files
files.download("client.xlsx")Le titre et les méta descriptions ne sont pas inclus dans l’ensemble de données de la Google Search Console. Nous les avons ajoutés à l’aide de cet extrait de code.
from requests_html import HTMLSession
def get_title_meta_description(page):
session = HTMLSession()
try:
r = session.get(page)
if r.status_code == 200:
title = r.html.xpath('//title/text()')
meta_description = r.html.xpath("//meta[@name='description']/@content")
#Inner utility function
def get_first(result):
if len(result) == 0:
return None
else:
return result[0]
return {"title": get_first(title), "meta_description": get_first(meta_description)}
else:
print(f"Failed to fetch page: {page} with status code {r.status_code}")
except:
print(f"Failed to fetch page: {page}")
return NoneEnsuite, nous pouvons l’exécuter sur toutes les URL à partir de la Search Console.
# let's get all of them
titles_and_meta_descriptions=dict()
import time
for page in pages:
print(f"Fetching page: {page}")
titles_and_meta_descriptions[page] = get_title_meta_description(page)
#add delay between requests
time.sleep(1)Nous avons du code dans le cahier qui le convertit en une trame de données. Ensuite, nous pouvons fusionner deux trames de données pour construire notre ensemble de formation initial.
merged_df=pd.merge(df, new_df, how="left", on="page")Assurez-vous de vérifier le code que j’ai utilisé pour remplir la feuille Google. J’ai trouvé une bibliothèque qui peut synchroniser un bloc de données avec Google Sheets. j’ai soumis un patch pour simplifier le processus d’authentification dans Google Colab.
# Save DataFrame to worksheet 'Client', create it first if it doesn't exist
spread.df_to_sheet(df, index=False, sheet='Client', start='A1', replace=True)Ressources pour en savoir plus
Il y a plus de code Python à réviser, mais comme j’ai documenté le bloc-notes Colab, il vaut mieux y lire et jouer avec.
Assurez-vous de vérifier le code qui accède à Google Search Console.
Une partie particulièrement intéressante pour moi est que la bibliothèque n’a pas pris en charge l’accès à partir de Google Colab.
J’ai examiné le code et identifié les modifications de code nécessaires pour prendre en charge cela.
J’ai apporté des modifications, j’ai vu qu’elles fonctionnaient et je les ai partagées avec le développeur de la bibliothèque.
Il les a acceptés et maintenant ils font partie de la bibliothèque et toute personne l’utilisant bénéficiera de ma petite contribution.
J’ai hâte de voir combien de SEO Python supplémentaires dans la communauté apportent des contributions open source aux bibliothèques et au code que nous utilisons tous.
L’apprentissage automatique est plus facile à apprendre visuellement.
Voici quelques liens sympas pour l’apprendre sans Math compliqué.
Davantage de ressources:
Crédits d’image
Toutes les captures d’écran prises par l’auteur, mai 2020



Commentaires récents